
Au cours des 12 à 18 derniers mois, l’intérêt pour les flux de travail agentiques s’est emballé. Ce qui n’était d’abord que des interactions en mode clavardage est devenu des systèmes capables de naviguer dans des logiciels, d’intégrer des actions, d’interroger des données et d’écrire du code. La promesse : des agents qui interprètent des objectifs et du contexte avec suffisamment de finesse pour automatiser le raisonnement sur des tâches allant du travail répétitif aux défis complexes et exigeants. L’infrastructure n’a toutefois pas suivi le même rythme : les modèles progressent rapidement, mais l’outillage reste fragmenté. Les équipes codent en dur des invites et des connecteurs et, même si les frameworks gèrent l’orchestration, la standardisation de la représentation des outils demeure un goulot d’étranglement. Les agents doivent alors deviner quels outils existent et comment les utiliser, ce qui fait de la composabilité autant un défi cognitif pour les modèles qu’un problème technique.
Nous avons déjà vu ce scénario. Les premiers logiciels dépendaient de protocoles fortement couplés jusqu’à ce que les API introduisent des interfaces réutilisables — avec SOAP (Simple Object Access Protocol) et XML (eXtensible Markup Language) dans les années 1990, puis REST (Representational State Transfer) qui a simplifié la communication dans les années 2000. Le Language Server Protocol (LSP), au milieu des années 2010, a normalisé la façon dont éditeurs et serveurs de langage échangeaient de l’information, rendant des fonctions avancées comme l’autocomplétion accessibles à grande échelle. Chaque étape a rendu les systèmes plus faciles à connecter et à étendre.
Les agents ont maintenant besoin d’un saut comparable. Les API statiques décrivent la mécanique, pas la signification, laissant aux modèles trop peu de contexte pour raisonner. Ce qui émerge plutôt est une couche d’abstraction lisible par les modèles, faite de schémas qui rendent les outils découvrables, interprétables et invocables lors de l’exécution. Tout comme le LSP a normalisé la communication entre éditeurs et serveurs de langage, le Model Context Protocol (MCP) vise à offrir une couche similaire pour les agents : une façon standard pour les outils de se décrire aux modèles et aux clients.
L’infrastructure actuelle est-elle suffisante ?
On demande souvent si les API existantes suffisent. Les modèles ne fonctionnent pas comme des programmes traditionnels et ne peuvent pas seulement s’appuyer sur des points de terminaison, créant un décalage fondamental entre la manière dont les API sont conçues et la façon dont les modèles raisonnent sur les outils. Les API déplacent des données, alors que les modèles ont besoin de sens. Un modèle doit comprendre non seulement où se trouve un point de terminaison, mais pourquoi il existe, comment il se relie aux autres et quoi faire en cas d’échec. Les spécifications OpenAPI capturent la surface, mais reflètent rarement l’intention, les modes d’usage ou les modes de défaillance dont les modèles ont besoin pour raisonner de façon fiable. Les palliatifs actuels échouent souvent à l’échelle, entraînant des comportements peu fiables.
Par exemple, pour analyser une demande de prêt, un modèle doit savoir quels outils prennent en charge l’extraction de documents, le score de crédit et la détection de fraude, comment les sorties de l’un alimentent l’autre, quels paramètres sont requis et comment gérer les données manquantes ou ambiguës. Sans contexte structuré, le système est forcé de deviner — et les erreurs s’accumulent.
Au‑delà des API, les agents ont besoin d’autres éléments qui apportent structure et fiabilité. Les manifestes MCP fournissent des métadonnées utiles au raisonnement; les couches d’orchestration coordonnent des flux multi‑étapes; la gestion du contexte suit l’état d’une étape à l’autre; l’observabilité relie journaux et exécution; et les systèmes d’identité appliquent des accès restreints. Ensemble, ces éléments font passer le modèle de « l’appel de fonctions à l’aveugle » au raisonnement avec des outils intégrés dans un système.
Le MCP est‑il la couche manquante ?
Le Model Context Protocol (MCP) a été introduit par Anthropic en novembre 2024 pour combler l’écart croissant entre modèles de langage, frameworks d’agents et outils externes. Le MCP n’est ni un nouveau framework d’agents, ni une couche d’orchestration, ni un produit, ni un modèle. C’est un standard qui permet aux outils de se décrire de manière cohérente, à la fois aux clients et aux modèles, et qui définit un processus structuré pour que les clients transmettent outils, données et invites à un modèle.
Au cœur du MCP, on trouve trois éléments :
- Manifestes : descriptions JSON des fonctions, paramètres et capacités d’un outil;
- Payloads : points d’accès structurés pour récupérer des données pertinentes à l’exécution;
- Entrée orientée modèle (Model-facing output) : un format paqueté combinant manifestes et payloads, fournissant une entrée structurée que le modèle peut raisonner.
Cette séparation permet au modèle de se concentrer sur l’intention et le choix des actions, tandis que le client gère la découverte, le formatage et l’exécution.
Le schéma suivant (en anglais) illustre l’interaction de ces composants dans une architecture MCP type.
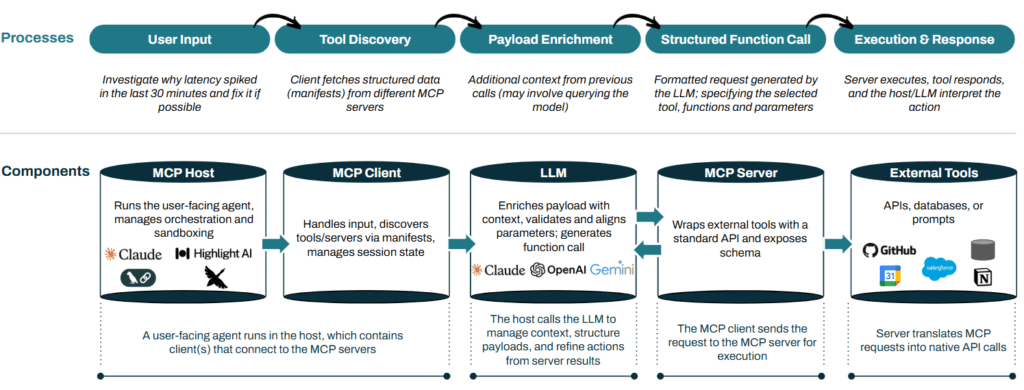
Aperçu de l’architecture du MCP
Cette approche isole proprement les rôles au sein d’un système agentique : les modèles interprètent l’intention et produisent des appels structurés; les clients exécutent avec l’information d’outils; les serveurs gèrent l’accès; les outils exposent leurs capacités dans un format standardisé. La communication est dynamique et itérative, le modèle et l’hôte/le client échangeant des messages en aller‑retour. Le MCP est conçu pour être agnostique au modèle et n’est lié ni à Claude ni à une pile en particulier.
Plutôt que de remplacer des frameworks comme AutoGen ou LangChain, le MCP les complète en standardisant la manière dont outils, données et invites sont décrits et transmis aux modèles, permettant aux frameworks de se concentrer sur la planification et l’orchestration. Le MCP en est toutefois encore à ses débuts : des éléments critiques comme l’identité, la gestion des accès et les outils développeur continuent d’évoluer.
Cartographie de l’architecture et des composants du MCP :
- Hôte MCP (MCP Host) : applications de premier niveau où les utilisateurs interagissent avec des agents (p. ex. applis de clavardage, IDE, tableaux de bord). Elles embarquent des clients MCP, gèrent l’I/O et coordonnent l’interaction complète entre utilisateurs, modèles, clients et outils.
- Clients MCP (MCP Clients) : couche d’exécution où les agents opèrent et interagissent avec les utilisateurs. Ils vivent dans les hôtes (UI), gèrent la construction des invites, la mémoire, la planification d’outils et le suivi d’état, et transforment les sorties des modèles en actions exécutables.
- Serveurs MCP (MCP Servers) : enveloppent des outils externes avec des manifestes normalisés, lisibles par machine, définissant pour chaque fonction son objectif, ses entrées et ses sorties, afin que les modèles puissent raisonner sur leur utilisation. Ils exposent aussi des ressources (p. ex. bases de données, ensembles d’invites) pour accélérer l’exécution.
- Exemples : un serveur MCP peut exister pour tout outil offrant une API; un serveur Gmail permettra les échanges de courriels; un serveur HubSpot autorisera des changements dans le CRM.
- Modèles (Models) : moteur de raisonnement du MCP, choisissant les outils, l’ordre et l’interprétation des entrées. Les configurations se veulent largement agnostiques, en s’alignant sur les schémas d’outils et le maintien du contexte.
- Exemples : GPT‑5, Claude‑4, Gemini 2.5.
- Génération et curation de serveurs (Server Generation and Curation) : la plupart des API ne sont pas prêtes MCP par défaut. La génération de serveurs transforme des points de terminaison existants en serveurs MCP standardisés — manifestes, payloads et métadonnées d’invites exploitables par les modèles.
- Places de marché MCP (MCP Marketplaces) : registres de serveurs compatibles MCP qui permettent aux agents de découvrir et d’utiliser des outils comme dans des app stores. Ils aident les agents à trouver de nouvelles capacités selon la tâche plutôt que de s’appuyer uniquement sur des API figées.
Ce qui nous excite :
1. Infrastructure de sécurité en évolution
À mesure que les outils MCP deviennent modulaires, l’OAuth traditionnel montre ses limites. OAuth fonctionne bien pour des applis fixes, avec clients pré‑enregistrés et portées statiques, mais les systèmes agentiques sont différents : ils lancent des agents éphémères qui raisonnent, agissent et chaînent des outils. Cela crée trois besoins importants en sécurité :
- Découverte — savoir quels agents existent dans l’entreprise et d’où ils viennent;
- Observabilité — voir en temps réel ce que font les agents et s’ils respectent les politiques;
- Permissions — leur donner uniquement l’accès nécessaire à une tâche, plutôt que des jetons larges et durables.
L’identité d’agent ressemble à l’identité machine… avec de l’agence. Contrairement à une clé API ou à un compte serveur, elle peut décider et s’adapter à l’exécution, ce qui bouscule les hypothèses d’OAuth. Les premiers essais pour boulonner OAuth au MCP ont échoué en confondant ressources et autorisation dans le même serveur, brouillant les frontières de confiance. Une approche plus robuste sépare les rôles : les clients gèrent les flux d’authentification, les serveurs appliquent des vérifications localement et une couche dédiée émet/vérifie les jetons. On observe d’ailleurs les premiers efforts pour séparer serveurs d’autorisation et serveurs de ressources.
Les développeurs ne veulent pas reconstruire l’acheminement, les sessions ou la gestion de la multi‑tenance à chaque fois : ils ont besoin d’un moyen standard d’accorder le bon accès, au bon moment. La pré‑autorisation d’« agents d’un outil » en supposant un comportement prévisible ne tient pas quand des tâches déclenchent de multiples agents éphémères aux besoins variés. La mémoire ajoute une complication : l’accès restreint peut fuiter d’une tâche à l’autre et la révocation d’un jeton ne retire pas ce que l’agent a déjà internalisé — même si, en pratique, ce n’est pas encore le principal verrou car les cas d’usage complexes émergent à peine. Reste une question ouverte : le MCP doit‑il intégrer des primitives d’auth ou s’appuyer entièrement sur de l’infra externe ? Un intermédiaire qui standardise des accès limités au niveau de la tâche — évitant les privilèges permanents — pourrait être la bonne voie (p. ex. URL+PKI, délégation d’autorité).
Parmi les acteurs prometteurs : Keycard, Natoma et Descope pour l’identité (autorisation, permissions); Orchid Security, Astrix et Reco pour la découverte et la posture; RunReveal et Zenity pour l’investigation et le monitoring; et notre entreprise en portefeuille Lakera, qui s’attaque aux risques de prompt injection et de fuite de données.
Nous partagerons bientôt un billet de suivi sur la sécurité des agents — restez à l’affût !
2. Infrastructure composable pour les systèmes multi‑agents
Les flux de travail agentiques peinent souvent à grande échelle, car construire et déployer des agents est plus difficile que prévu. Les agents verticaux passent de copilotes étroits à de véritables moteurs de flux, grâce à des cadres modulaires comme MCP et A2A. Un agent de codage, par exemple, peut évoluer de la rédaction de code à la correction de bogues, la gestion de tickets et la consignation d’avancées — en rapprochant des étapes aujourd’hui dispersées entre des outils déconnectés. Mais la plupart des implémentations surestiment les capacités des agents : le contexte se brise, l’observabilité reste superficielle et les tests se concentrent trop sur les invites. Les serveurs MCP rencontrent des problèmes similaires (spécificités clients, traces manquantes), d’où le besoin d’un meilleur outillage local et distant.
La modularité et l’orchestration demeurent des goulots d’étranglement : les conceptions maître → sous‑agents sont encore précoces et fragiles; les boucles de rétroaction et l’observabilité à l’exécution sont incomplètes; et fermer la boucle agentique — agir, observer, s’ajuster sans perdre le contexte — reste l’un des défis les plus ardus. Il y a là des opportunités claires en observabilité, gestion d’échecs à l’exécution et documentation lisible par machine qui soutient la rétention du contexte à travers les flux.
La mise en œuvre et l’accompagnement ajoutent une couche supplémentaire de friction : l’expertise technique correspond mal à la complexité des flux, ce qui complique l’adoption, surtout dans les organisations intermédiaires et les grandes entreprises. Les arbitrages « acheter vs construire » deviennent plus critiques à mesure que les applis évoluent, tandis qu’une certaine fragilité persiste dans les entreprises émergentes. Par exemple, Langfuse est perçu comme performant pour le débogage d’étapes individuelles, mais tester des flux multi‑étapes bout‑en‑bout reste difficile. De même,Braintrust offre des évaluations flexibles, mais leur intégration dans des agents multi‑étapes demeure un irritant.
Perspectives : un potentiel précoce, mais encore inachevé
Nous croyons qu’avec le MCP, de nouveaux composants et opportunités vont émerger, même si les voies de monétisation restent floues. La découverte et les places de marché pourraient jouer un rôle, mais ont tendance à se commoditiser. Des répertoires comme le registre ouvert d’Anthropic et des plateformes comme Smithery hébergent déjà des milliers de serveurs, ce qui rend la simple liste ou la création basique peu différenciée; bâtir des portails de serveurs est une autre piste. La découverte d’outils sera mieux servie par des fonctions de recherche et de recommandation directement intégrées aux agents, influencées par les outils auxquels l’utilisateur est déjà abonné. Au‑delà de la découverte, le MCP ouvre des possibilités d’orchestration multi‑agents, mais ces terrains sont encore peu éprouvés à grande échelle. Les besoins fondamentaux persisteront quels que soient les cadres dominants, et plusieurs approches coexisteront.
La véritable opportunité se situe dans une infrastructure agnostique aux protocoles, capable de servir de base stable à travers les écosystèmes d’agents. Au delà de ceci, des extensions comme la coordination d’un agent maître avec des sous‑agents orientés tâches, le lien entre observabilité et état des flux, et la mise en place d’une rétroaction continue seront déterminantes. Les outils qui soutiennent de façon fiable la rétention du contexte, l’évaluation à l’exécution, le débogage et la gestion de versions sont ceux qui ont le plus de chances de constituer une base durable et de tirer l’adoption.
Si vous construisez dans cet espace (ou des espaces adjacents) ou souhaitez explorer l’avenir de l’infrastructure agentique, faites-nous signe !
Sources et influences :
- « Introducing the Model Context Protocol » ; Anthropic (LIEN)
- « Model Context Protocol (MCP), an overview » ; Phil Schmid (LIEN)
- « Model Context Protocol — Deep Dive » ; Practical AI Podcast (LIEN)
- « Intro to APIs: History of APIs » ; Postman (LIEN)
- Palo Alto Networks — LIVEcommunity (LIEN)
- Discussions Reddit et Hacker News